Emo AI by Alibaba, Image to Face & Body Video
Let me start by saying: this is simply freaking amazing and scary at the same time. I really don’t think we stand a chance of telling real from fake in a few years (if not months).
If the following video does not amaze you and scare you at the same time, you are not human. The video is created using only an image shown on left in video.
And you think it could not get even more amazing? Check out the character AI Lady from Sora in this video (Vocal Source: Dua Lipa - Don't Start Now):
So what the heck is EMO? Best we can find out right now is: "Emote Portrait Alive: Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions" and is from the Institute for Intelligent Computing, Alibaba Group.
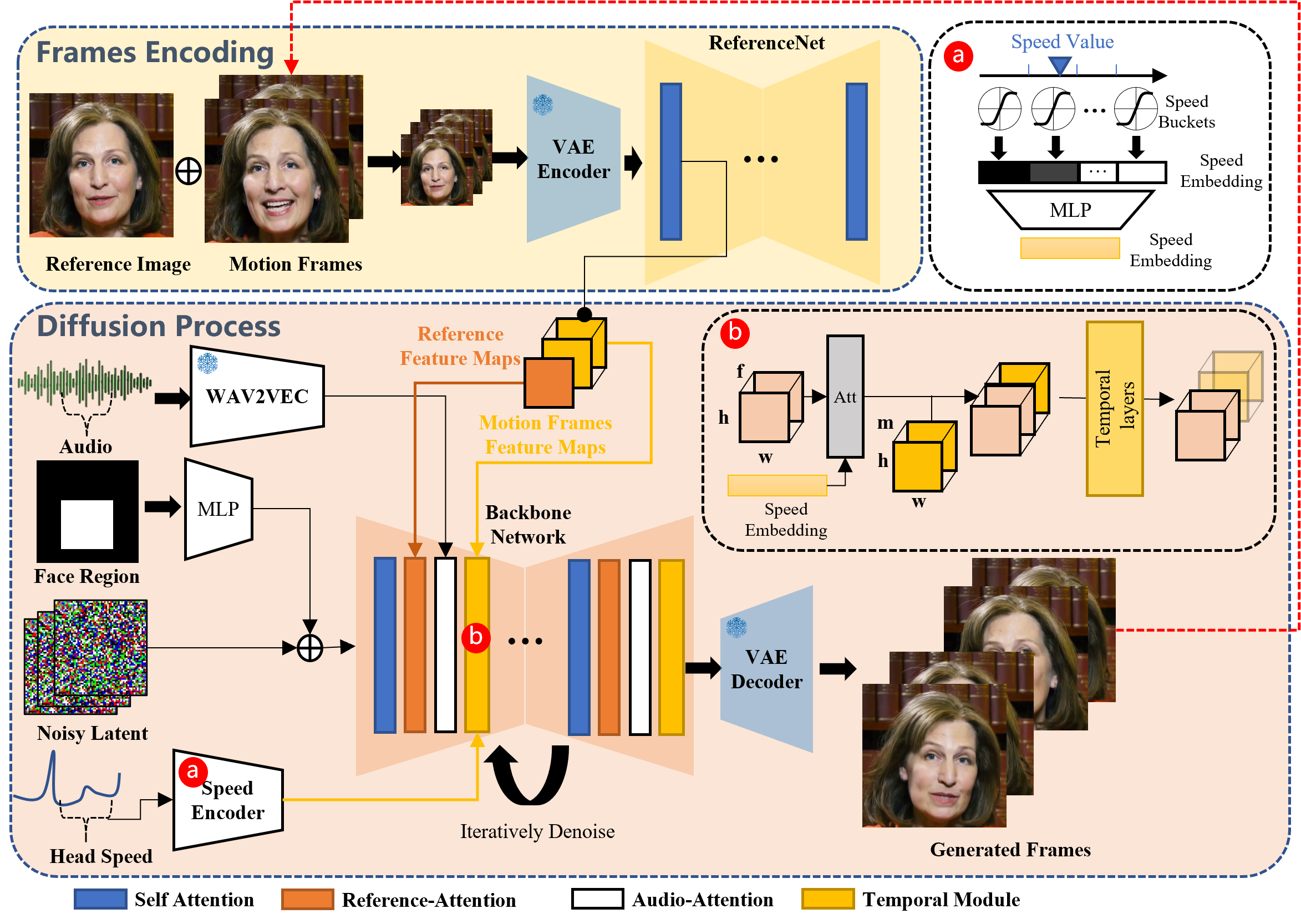
According to the source, the method involved flows like this:
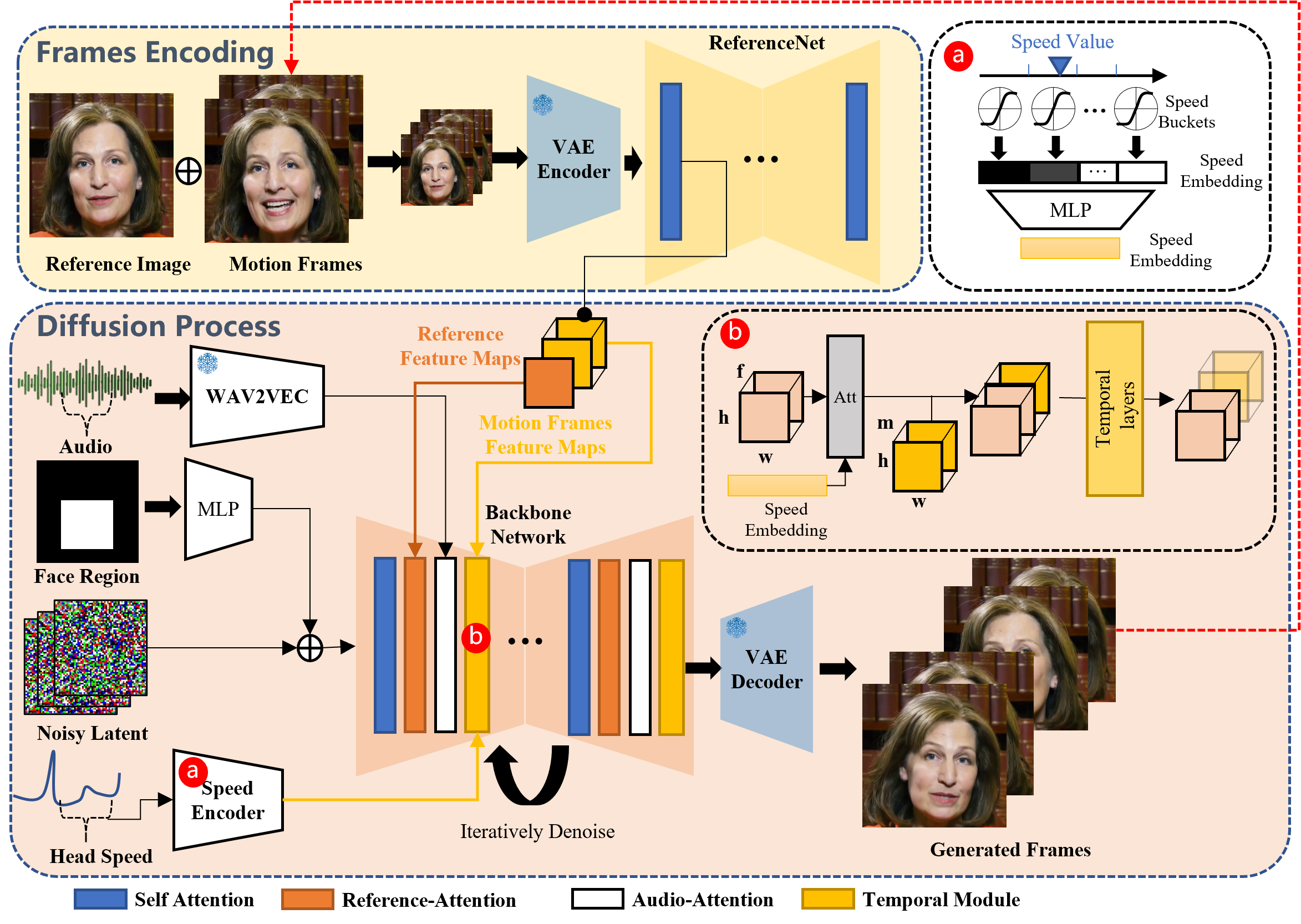
Overview of the proposed method. Our framework is mainly constituted with two stages. In the initial stage, termed Frames Encoding, the ReferenceNet is deployed to extract features from the reference image and motion frames. Subsequently, during the Diffusion Process stage, a pretrained audio encoder processes the audio embedding. The facial region mask is integrated with multi-frame noise to govern the generation of facial imagery. This is followed by the employment of the Backbone Network to facilitate the denoising operation. Within the Backbone Network, two forms of attention mechanisms are applied: Reference-Attention and Audio-Attention. These mechanisms are essential for preserving the character's identity and modulating the character's movements, respectively. Additionally, Temporal Modules are utilized to manipulate the temporal dimension, and adjust the velocity of motion.
You can see more video examples by visiting this site.


